Capítulo 8 Muestreo y estimación
8.1 Muestreo Estadístico
El muestreo estadístico es el mecanismo por el que se selecciona la muestra a partir de una población. A grandes rasgos, hay que determinar cómo se seleccionan los elementos de la muestra y cuántos se seleccionan. Este tamaño muestral lo representamos por \(n\), y a menudo se habla de “la \(n\)” del experimento (o del estudio, en general). El tamaño de la muestra lo determina la característica que queremos estudiar, que se representada por una variable aleatoria. En función del modelo de distribución de probabilidad que sigue la variable aleatoria, se determina el tamaño de la muestra.
Es importante diferenciar las muestras estadísticas de las muestras “biológicas” o de materiales. A veces estarán relacionadas, pero otras veces serán cosas totalmente distintas y no relacionadas.
El muestreo es muy importante en cualquier estudio estadístico para poder extraer conclusiones válidas y tomar decisiones sobre la poblaciónrespaldadas por los datos. El aspecto más importante es que tienen que ser muestras representativas de la la población. Para asegurar esta representatividad, utilizamos métodos probabilísticos, de forma que los sesgos (falta de representatividad) que se produzcan sean achacables únicamente al azar, y no a otro tipo de cuestiones.
No siempre realizamos estudios estadísticos basados en una muestra extraída ad-hoc, sino que analizamos datos disponibles que se han recogido o están disponibles sin realizar un muestreo. Con estos datos podemos hacer estudios observacionales (frente a los experimentos diseñados) siempre teniendo en cuenta que puede haber sesgos y la muestra no represente a la población. Por otra parte, muchas veces no es posible hacer un muestreo completamente aleatorizado, y entonces podemos recurrir a muestreos cuasi-probabilísticos. En cualquier caso, hay que intentar evitar a toda costa las muestras “de conveniencia”, y plantearnos en todo momento si podemos considerar que es representativa de la población.
La muestra debe representar a la población.
8.2 Muestreo probabilístico
Entre los muestreos probabilísticos, podemos elegir entre muestreo aleatorio simple (MAS), muestreo estratificado, muestreo por conglomerados y muestreo sistemático. Salvo en este último, en los demás necesitamos una enumeración e identificación de los individuos de la población. En el muestreo sistemático, necesitamos solamente un orden.
El muestreo aleatorio simple es el más sencillo. Todos los elementos de la población tienen la misma probabilidad de pertenecer a la muestra. Requiere tener identificados de alguna manera a los individuos de la población, y es adecuado en poblaciones pequeñas, homogéneas, en las que no hay patrones conocidos.
Se dispone del listado de depuradoras de agua de una región y se quiere estudiar alguna característica específica de instalaciones sin hacer análisis a todas las depuradoras. Se seleccionan al azar un número de depuradoras determinado.
El muestreo estratificado es más adecuado en poblaciones no homogéneas. Se conocen grupos dentro de la población, que son diferentes entre ellos, pero las subpoblaciones dentro de los grupos son homogéneas. Además, se conoce algo sobre la distribución de la característica en cada grupo. Entonces se obtiene una muestra aleatoria de cada uno de los grupos (estratos). Este tipo de muestreo no es apropiado en poblaciones pequeñas.
Si estamos estudiando una población en la que se sabe que la variable de interés se comporta de forma diferente en distintas CCAA, se consideran estos estratos y se obtiene una submuestra de cada uno (por ejemplo en el caso anterior de las depuradoras).
El muestreo por conglomerados también asume que se dispone de grupos en la población, la diferencia es que en este caso los grupos son homogéneos entre sí (se parecen). Pero dentro de cada grupo la variable se comporta de forma heterogénea. Puede existir una jerarquía (conglomerados dentro de los conglomerados). Entonces se obtiene una muestra de grupos (no de individuos). Después se pueden estudiar TODOS los individuos de los grupos de la muestra, o aplicar otro muestreo dentro (por ejemplo, estratificado). Es adecuado cuando es más fácil llegar a todos los elementos de un grupo.
Se estudian hábitos de higiene en las familias en una ciudad. Se divide en barrios y se elige muestra de barrios. Dentro de cada barrio, se eligen aleatoriamente edificios, y se estudian todas las familias del edificio
No siempre tenemos la lista de elementos, como en los casos anteriores. Pero sí podemos “ordenarlos” de alguna manera, por ejemplo, conforme llegan muestras (en el sentido biológico) a un laboratorio. Entonces podemos realizar un muestreo sistemático. Para poder usarlo es importante estar seguro de que la característica no depende del orden. Entonces, se elige un punto de partida (idealmente aleatorio) y se toman elementos separados a distancia \(k\) (coeficiente de elevación). Esta distancia puede referirse al número de individuos, por ejemplo, cada 10 individuos que llegan, o a un periodo de tiempo si llegan de forma más o menos regular, por ejemplo, cada 20 minutos. Se puede aplicar en vez de MAS en cualquiera de las situaciones anteriores.
En la producción de un fertilizante en bolas, se tomarán muestras de 10 bolas cada hora. Se elige aleatoriamente un instante la primera hora, y a partir de ahí cada 60 minutos se tomarán las siguientes 10 bolas.
Cuando no es posible hacer un muestreo probabilístico, algunas veces pueden ser válidos muestreos no probabilísticos. Entonces podremos hacer estudios observacionales, e incluso aplicar técnicas de inferencia estadística, pero con ciertas precauciones. Las conclusiones pueden no ser válidas para toda la población, y hay que tenerlo en cuenta. Hay que procurar que, al menos cualitativamente, podamos presumir que la muestra representa a la población, o al menos no tener evidencias de que no es así. Los estudios observacionales (sobre datos que están ahí) son también muy valiosos. Si estos estudios nos dan luz sobre algo suficientemente importante, puede merecer la pena diseñar un experimento para confirmar las conclusiones.
8.3 Parámetros y estimadores
Recordemos que los parámetros se definen sobre una Variable Aleatoria \(X\) de la población. Son Desconocidos, pero siguen un modelo de distribución de probabilidad teórica de la variable aleatoria subyacente. En general, los queremos estimar mediante inferencia paramétrica. Los estadísticos son valores que se calculan con los datos de la muestra. En cada muestra serán distintos, es decir, habrá variabilidad, y por tanto son variables aleatorias, que siguen también una distribución de probabilidad. Esa distribución de probabilidad del estadístico es lo que llamamos distribución en el muestreo.
\(\mu, \sigma^2 \text{ y } \pi\) representan los parámetros media, varianza y proporción de una determinada característica en la población. Son desconocidos, y dependen de la distribución de la característica en estudio. \(\bar x, s^2 \text{ y } p\) son estadísticos calculados con los \(n\) datos de una muestra.
Un estimador es un estadístico mediante el cual estimamos el valor de un parámetro. Esa estimación estará sujeta a un error, que se puede cuantificar si se ha seguido un muestreo probabilístico. El error va a depender de las propiedades del estimador y del tamaño de la muestra. Representamos con \(\hat \mu = \bar x\) que la media muestral \(\bar x\) es un estimador de la media poblacional \(\mu\)
- Proporción: \(\hat \pi = p\)
- Media: \(\hat \mu = \bar x\)
- Varianza: \(\hat \sigma^2 = s^2 = \frac{1}{n-1}\left( \sum x_i^2 - n \bar x^2 \right )\)
Para determinar qué estimador utilizar para un parámetro, se estudia su distribución en el muestreo. Las siguientes son propiedades deseables de los estimadores:
Insesgado: Que la esperanza del estimador sea igual al verdadero valor del parámetro.
Eficiente: Que tenga la mínima varianza posible.
Consistente: Que tenga menor variabilidad a mayor tamaño de muestra.
8.4 Distribución en el muestreo de los principales estadísticos
8.4.1 Media muestral
Sea la variable aleatoria \(X\) con \(E[X] = \mu\) y \(V[X] = \sigma^2\). Obtenemos muestras de tamaño \(n\): \(x_1, \ldots, x_i, \ldots, x_n\). Usamos la media muestral como estimador de la media poblacional:
\[\hat \mu = \bar x = \frac 1 n \sum\limits_1^n x_i.\]
Entonces \(\overline X_{\{n\}}\) es la variable aleatoria “media de la característica \(X\) en muestras de tamaño \(n\)”, y por las propiedades de la esperanza y la varianza:
\(E[\overline X_{\{n\}}]\) = \(\mu\),
\(V[\overline X_{\{n\}}] = \frac{\sigma^2}{n}\).
8.4.2 Teorema Central del Límite
Sean \(X_1, \ldots, X_n\) variables aleatorias independientes e idénticamente distribuidas, con media \(\mu\) y varianza \(\sigma^2\). Y sea \(\overline X\) el promedio de esas variables aleatorias:
\[\overline X = \frac 1 n \sum\limits_{i=1}^n X_i.\]
Entonces, para \(n\) suficientemente grande, la variable aleatoria \(\overline X_{\{n\}}\) sigue una distribución normal de media \(\mu\) y varianza \(\frac{\sigma^2}{n}\):
\[\overline X_{\{n\}} \sim N\left(\mu; \frac{\sigma}{\sqrt{n}} \right).\]
El Teorema Central del Límite nos va a permitir hacer inferencia de cualquier variable aleatoria \(X\) utilizando las propiedades de la distribución normal.
8.4.3 Varianza muestral
La varianza poblacional, calculada con \(n\) en el denominador, es un estimador sesgado:
\[E\left[\frac 1 n \sum (x_i-\bar x)^2 \right] = \frac{n}{n-1}\sigma^2.\]
Por eso usamos la “cuasivarianza” o varianza muestral:
\[\hat \sigma^2 = s^2 = \frac{ 1}{ n-1} \sum (x_i-\bar x)^2.\] Se cumple que:
- \(E[s^2] = \sigma^2\)
- \(V[s^2] = \frac{2\sigma^4}{n-1}\)
Para determinar la distribución en el muestreo de la varianza muestral, primero tenemos que definir la distribución \(\chi^2\), que tiene un único parámetro, los grados de libertad \(n\). Se define como la suma de \(n\) variables aleatorias normales independientes estandarizadas al cuadrado:
\[\chi^2_n = Z_1^2 + \ldots + Z_n^2;\quad Z_i \sim N(0; 1)\forall i; \quad E[\chi^2_{n}]=n; \quad V[\chi^2_{n}]=2n.\]
Se cumple, independientemente de la distribución de \(X\), que:
\[\frac{(n-1)s^2}{\sigma^2}\sim \chi^2_{n-1},\] que es la distribución que usaremos para hacer inferencia sobre la varianza de la población.
La distribución \(\chi^2\) es positiva y asimétrica. Esta asimetría puede tomar formas muy diversas. A medida que aumentan los grados de libertad, esta asimetría es menos pronunciada, véase la Fig. 8.1.
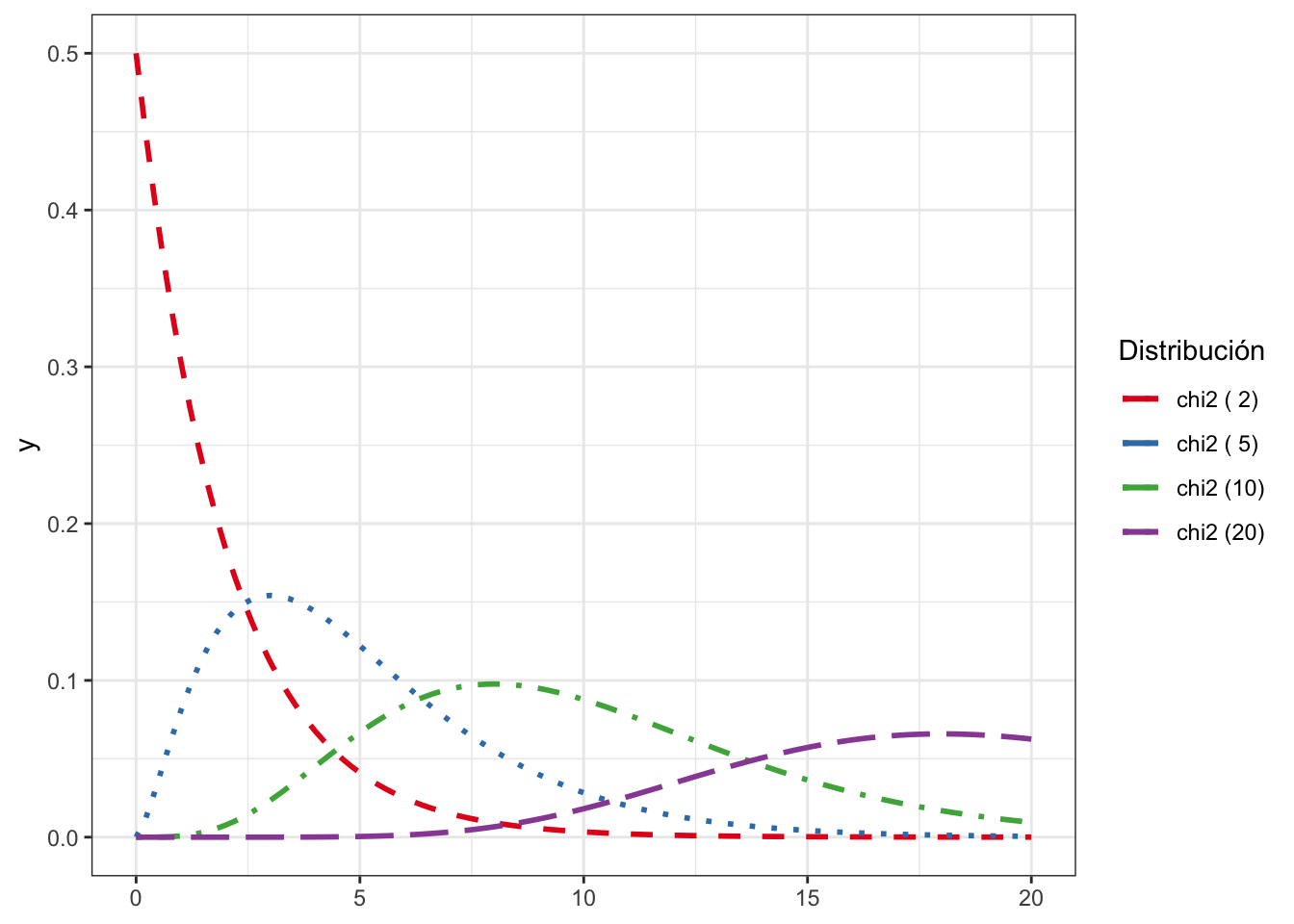
Figura 8.1: Distribución \(\chi^2\) para distintos grados de libertad
8.4.4 Proporción muestral
Sea la variable aleatoria \(X:\) Número de elementos de la muestra de tamaño \(n\) que presentan la característica en estudio. Entonces al extraer la muestra, se obtienen valores \(x \in \{1, \ldots, n\}\), y el estadístico proporción muestral será \(p = \frac x n\). Entonces, la probabilidad de que el parámetro \(\pi\) tome un valor determinado \(p=\frac x n\), es equivalente a la probabilidad de que la variable \(X\) tome el valor \(x\):
\[P[\pi = p] = P\left [\pi = \frac x n\right] = P[X = x].\]
Por tanto, la distribución exacta en el muestreo de \(\hat \pi = p\) es una Binomial de parámetros \(n\) y \(\pi\).
Como la binomial es una suma de distribuciones de Bernoulli, entonces \(p\) es una media: \(p=\frac X n = \frac{\sum X_i}{n}\), y por el Teorema Central del Límite:
\[P = \frac{X}{n}\approx N\left(\pi, \sqrt{\frac{\pi(1-\pi)}{n}}\right).\] También se puede definir la distribución en el muestreo del número de elementos de la muestra con la característica, \(X\):
\[X=np \sim N(n\pi, \sqrt{n\pi(1-\pi)}.\]
8.5 Tamaño muestral para estimar la media
Recordemos que no conocemos los parámetros de la población, por tanto necesitamos una forma de estimar el error que estamos cometiendo. Definimos entonces el error estándar de la media (Standard Error, SE) como:
\[SE=\frac{s}{\sqrt{n}}\]
como medida de dispersión del promedio muestral. A veces se usa error típico como sinónimo.
A mayor tamaño muestral, menor variabilidad, y menor error en las estimaciones.
El error depende del tamaño muestral, y también podemos determinar cuál debe ser el tamaño de la muestra \(n\) para cometer, como máximo, un determinado error \(e\). Y esto lo haremos con una cierta confianza. En los métodos paramétricos, este nivel de confianza tiene que ver con el muestreo. Indica la proporción de veces que cometo un error inferior a \(e\) si repito el muestreo un número grande de veces. Se suele expresar como porcentaje, por ejemplo 95%, 99%, etc.
Definimos el nivel de significación \(\alpha\) como el complementario del nivel de confianza. Por ejemplo, para un nivel de confianza del 95% tendríamos un nivel de significación de 0,05. Entonces, para la media de una variable aleatoria \(X\) que sigue una distribución normal, si tipificamos:
\[\frac{\overline X- \mu}{\frac{\sigma}{\sqrt{n}}}\sim N(0; 1).\]
Entonces para cumplir la confianza indicada anteriormente, se debe dar la siguiente condición:
\[\begin{equation} P\left[-z_{\frac{\alpha}{2}}<\frac{\overline x- \mu}{\frac{\sigma}{\sqrt{n}}}<z_{\frac{\alpha}{2}}\right] = 1-\alpha, \tag{8.1} \end{equation}\]
donde \(z_{\frac{\alpha}{2}}\) es el cuantil de la distribución normal estandarizada para una probabilidad de \(1-\frac{\alpha}{2}\).
Normalmente se omite en \(z_{\frac{\alpha}{2}}\) el símbolo “\(1-\)” por comodidad al ser simétricos: \(z_\frac \alpha 2= - z_{1-\frac \alpha 2}\), véase la Fig. 8.2.
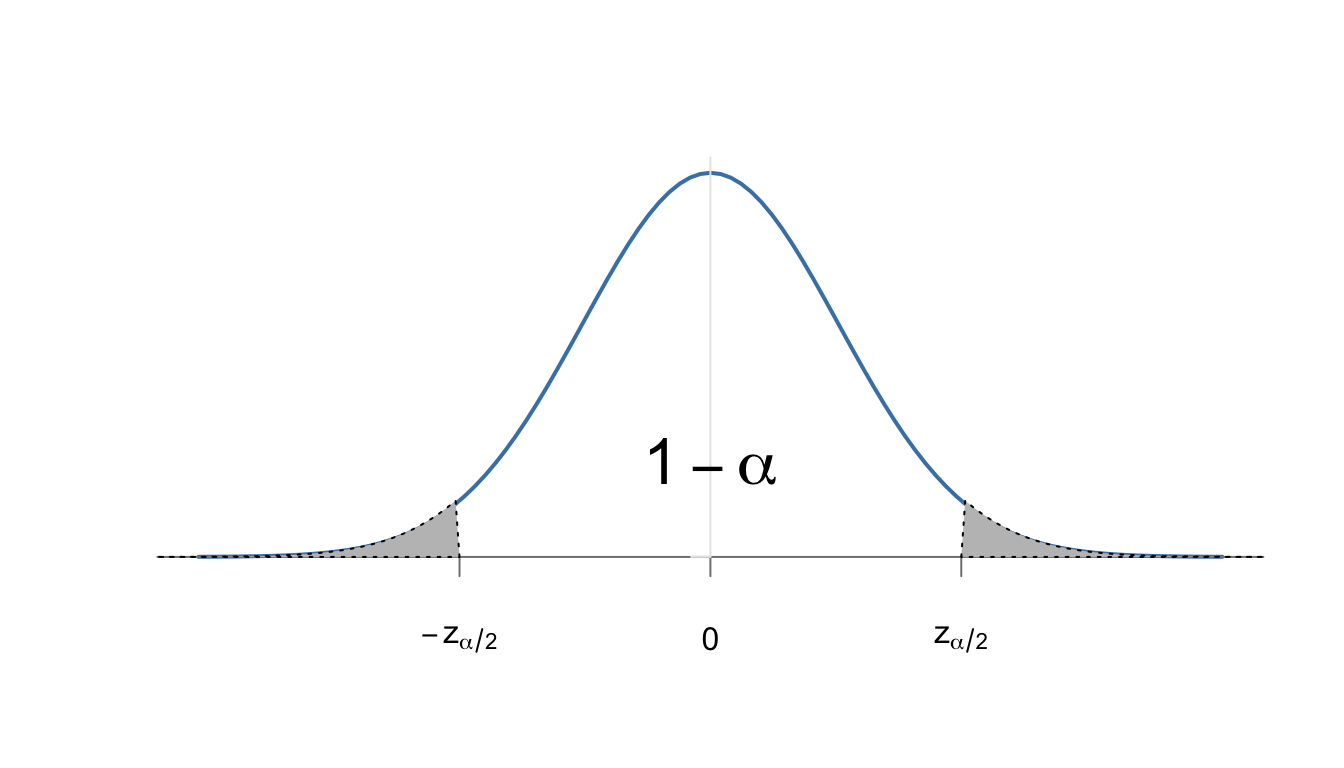
Figura 8.2: Representación del nivel de confianza , 1-\(lpha\), y el nivel se significación, \(lpha\), repartido en las dos colas de la distribución normal.
Para un nivel de significación \(\alpha = 0{,}05\), \(z_{\frac{\alpha}{2}} \simeq 1{,}96\). Podemos encontrar este valor en las tablas o con más precisión usando la siguiente expresión de R:
qnorm(0.95)Despejando \(\mu\) en la ecuación (8.1):
\[P\left[\overline x-z_{\frac{\alpha}{2}} \frac{\sigma}{\sqrt{n}}< \mu < \overline x+z_{\frac{\alpha}{2}} \frac{\sigma}{\sqrt{n}}\right] = 1-\alpha.\]
De aquí, el error que estoy cometiendo un \(100 \times (1-\alpha)\)% de las veces al estimar la media \(\mu\) con la media muestral \(\bar x\) y muestras de tamaño \(n\) es:
\[e=z_{\frac{\alpha}{2}} \frac{\sigma}{\sqrt{n}},\]
de donde despejando \(n\), tenemos una expresión general para calcular el tamaño de muestra:
\[n = \frac{z_{\frac{\alpha}{2}}^2 \sigma^2}{e^2}.\]
Esta expresión nos sirve tal cual para calcular el tamaño de muestra necesario para estimar la media poblacional de una variable aleatoria normal con varianza conocida \(\sigma^2\), y tamaño poblacional grande. Si el tamaño de la población es pequeño y conocido, \(N\), entonces el tamaño de la muestra se calcula con esta otra fórmula:
\[n = \frac{N\cdot z_{\frac{\alpha}{2}}^2 \cdot \sigma^2}{e^2\cdot (N-1)+ z_{\frac{\alpha}{2}}^2 \cdot \sigma^2},\]
Si la varianza es desconocida, sustituimos \(\sigma\) por \(s\). Si no tenemos \(s\), se estima el caso más desfavorable.
Queremos estimar la valoración que hacen los clientes de un determinado servicio energético en una puntuación de 0 a 10. El caso más desfavorable (para el tamaño de la varianza) sería que la mitad de los clientes contestaran un 0 y la otra mitad un 10. O, equivalentemente, que contestara un cliente con un cero y otro con un 10. Entonces, la varianza \(s^2\) estaría entre 50 \((n=2)\) y 25 (\(n\) grande). El tamaño de muestra mínimo para estimar la puntuación media en una población grande y no equivocarnos en más de \(e = 1\) punto con una confianza del 95% sería de \(n =192\) clientes.
\[n = \frac{1.96^2\cdot 50}{1^2}\simeq 192\]
var(c(0, 10))
#> [1] 50
var(rep(c(0, 10), each = 100))
#> [1] 25.12563
(qnorm(0.975)^2*50)/(1^2)
#> [1] 192.0729Lo más normal es que el cálculo de \(n\) nos dé un número decimal. Tomaremos siempre el número entero redondeando al alza, para garantizar que la confianza es, al menos, de \((1-\alpha)%\), ya que a mayor tamaño muestral, mayor confianza. Si se hiciera un redondeo al entero inferior, la confianza sería menor de la deseada.
8.6 Tamaño muestral para estimar la proporción
Asumimos que serán muestras grandes, y aplicando la aproximación de la distribución binomial por la normal, tenemos que para poblaciones grandes:
\[n = \frac{z_{\frac{\alpha}{2}}^2 \cdot \pi\cdot(1-\pi)}{e^2},\] y para poblaciones pequeñas de tamaño \(N\):
\[n = \frac{N\cdot z_{\frac{\alpha}{2}}^2\cdot \pi\cdot(1-\pi)}{e^2\cdot (N-1)+ z_{\frac{\alpha}{2}}^2 \cdot \pi\cdot(1-\pi)}.\]
Si no hay información sobre el parámetro \(\pi\), se toma el caso más desfavorable, que siempre es: \(\pi = (1-\pi) = 0{,}5.\)
8.7 Estimación puntual
Uno de los objetivos de la inferencia estadística es la estimación de los parámetros de la población, a partir de los datos de la muestra. Mediante la estimación puntual daremos un valor único como estimación del parámetro, mediante un estadístico (función aplicada a los datos de la muestra) que usaremos como estimador. Así, para los parámetros más importantes se han establecido los siguientes estimadores puntuales:
- Proporción: \(\hat \pi = p = \frac x n\).
- Media: \(\hat \mu = \bar x = \frac{\sum x_i}{n}\).
- Varianza: \(\hat \sigma^2 = s^2 = \frac{1}{n-1}\left( \sum x_i^2 - n \bar x^2 \right )\).
Se pueden determinar los mejores estimadores para cualquier parámetro de una distribución de probabilidad concreta, que cumplan las características de insesgadez, eficiencia y consistencia. Para ello se pueden utilizar diversos métodos, como el método de los momentos o el de máxima verosimilitud, que no se tratan en este texto aplicado.
La normativa de calidad del agua72 determina que el parámetro pH debe estar entre 6.5 y 9.5 unidades de pH. Se obtienen 30 muestras aleatorias en hogares y se mide el pH, registrando también si el edificio tiene depósito de agua y la cantidad de antimonio en \(\mu\)g/l. Los datos se muestran en la tabla 8.1. Podríamos estimar con estos datos la media de pH en la población, la varianza, y la proporción de edificios con depósito de agua, utilizando los estimadores indicados anteriormente.
pH |
deposito |
antimonio |
|---|---|---|
7.687 |
Sí |
0.94 |
8.092 |
No |
1.03 |
7.582 |
No |
1.06 |
8.798 |
No |
0.99 |
8.165 |
No |
1.07 |
7.590 |
No |
1.03 |
8.244 |
No |
0.95 |
8.369 |
Sí |
1.03 |
8.288 |
No |
0.91 |
7.847 |
Sí |
1.11 |
8.756 |
No |
1.16 |
8.195 |
Sí |
0.97 |
7.689 |
No |
0.92 |
6.893 |
No |
1.05 |
8.562 |
No |
0.99 |
7.978 |
Sí |
1.19 |
7.992 |
Sí |
1.00 |
8.472 |
No |
1.06 |
8.411 |
Sí |
1.00 |
8.297 |
Sí |
0.94 |
8.459 |
No |
1.02 |
8.391 |
Sí |
0.86 |
8.037 |
No |
1.12 |
7.005 |
No |
1.01 |
8.310 |
Sí |
1.17 |
7.972 |
No |
1.04 |
7.922 |
Sí |
0.94 |
7.265 |
No |
1.05 |
7.761 |
No |
0.93 |
8.209 |
No |
0.90 |
El siguiente código calcula la media muestral del pH, la varianza muestral del pH, y la proporción muestral de edificios con depósito de agua (y por tanto también sin depósito de agua). Los datos se importan directamente de una url. Resultan las siguientes estimaciones puntuales:
\[\hat{\mu} = \bar{x} = 8.04\] \[\hat{\sigma}^2= s^2 = 0.21\] \[\hat{\pi}= p = \frac{11}{30} = 0.37\]
mean(ph1$pH)
#> [1] 8.041267
var(ph1$pH)
#> [1] 0.2134909
prop.table(table(ph1$deposito))
#>
#> No Sí
#> 0.6333333 0.36666678.8 Estimación por intervalos
Al hacer la estimación puntual de cualquier parámetro, digamos genéricamente \(\theta\), estamos cometiendo un error \(e\). Este error se puede cuantificar gracias a la distribución en el muestreo del estadístico que estemos usando como estimador. Y entonces podemos construir intervalos de confianza (IC) para el parámetro que estamos estimando.
El intervalo puede ser bilateral, con dos límites inferior \((LI)\) y superior \((LS)\), de modo que \(\theta \in[\mathit{LI}, \mathit{LS}]\) para los que se cumpla que:
\[P[\mathit{LI} < \theta < \mathit{LS}]=1-\alpha.\] Nótese que la probabilidad de que el parámetro sea mayor que el límite superior o menor que el límite inferior será \(\frac \alpha 2\), véase la Fig. 8.2. Aquí, \(1-\alpha\) es el nivel de confianza (se expresa a menudo como porcentaje), y \(\alpha\) es el nivel de significación.
Los intervalos de confianza también pueden ser unilaterales, cuando solamente nos interesa saber un umbral mínimo o máximo del verdadero valor del parámetro. Estos intervalos tienen un único límite inferior o superior, y se pueden expresar como:
- \([LI, \infty)\): \(P[\theta > LI] = 1-\alpha\).
- \((-\infty, LS]\): \(P\theta < LS] = 1-\alpha\).
La diferencia principal es que, con la misma confianza, queremos asegurarnos de que el verdadero valor del parámetro no es mayor que el límite superior o no es menor que el límite inferior (pero el lado opuesto nos da igual).
La normativa de calidad del agua mencionada en el ejemplo del pH, determina un valor paramétrico de 5 \(\mu\)g/l de antimonio como límite máximo. En este caso, el intervalo de confianza que nos interesará es un intervalo unilateral con un único límite superior, ya que la característica en estudio es “cuanto menor, mejor”.
Para determinar los intervalos de confianza, nos basamos en la distribución en el muestreo de cada estimador \(\hat \theta\). A continuación deduciremos las fórmulas para los intervalos de confianza de la media, la varianza y la proporción.
8.8.1 Intervalo de confianza para \(\mu\): \(\sigma^2\) conocida
La media muestral de tamaño \(n\) sigue una distribución Normal con media \(\mu\) y varianza \(\frac{\sigma^2}{n}\). Por tanto, tipificando, tenemos la siguiente distribución en el muestreo:
\[\begin{equation} \frac{\overline X- \mu}{\frac{\sigma}{\sqrt{n}}}\sim N(0; 1). \tag{8.2} \end{equation}\]
Para un nivel de confianza \(1-\alpha\) determinado, si buscamos un intervalo bilateral tenemos que:
\[P\left[-z_{\frac{\alpha}{2}}<\frac{\overline x- \mu}{\frac{\sigma}{\sqrt{n}}}<z_{\frac{\alpha}{2}}\right] = 1-\alpha.\]
Y despejando \(\mu\) tendremos que, con una confianza de \(1-\alpha\), el verdadero valor del parámetro \(\mu\) estará en el intervalo:
\[\mu \in \left [\bar x - z_{\frac{\alpha}{2}}\cdot \frac{\sigma}{\sqrt{n}};\; \bar x + z_{\frac{\alpha}{2}}\cdot \frac{\sigma}{\sqrt{n}}\right].\]
O, de forma más compacta:
\[\begin{equation} \boxed{\bar x \pm z_{\frac{\alpha}{2}}\cdot \frac{\sigma}{\sqrt{n}}} \tag{8.3} \end{equation}\]
La estimación puntual de la media del pH en las
30 viviendas muestreadas en el ejemplo anterior, está sujeta a un cierto error. Vamos a
dar la estimación como un intervalo de confianza al 95%. Supongamos que la varianza
es conocida e igual a \(\sigma^2 = 0{,}25\). Para varianza conocida
no hay una función específica que nos dé el intervalo de confianza, pero es
muy fácil obtenerlo con la siguiente expresión, donde c(-1,1)* nos permite
obtener dos números, uno sumando y otro restando aquello a lo que multiplica,
y qnorm(0.975) nos da el valor de \(z_{\frac \alpha 2}\), dado que si
\(1-\alpha=0{,}95 \implies \frac \alpha 2 = \frac{ 0{,}05}{ 2} = 0{,}025\).
Recordemos que por simplicidad escribimos \(z_{\frac{\alpha}{2}}\) pero tomamos el cuantil de la distribución normal en \(1-\frac \alpha 2\), es decir, 0,975. En la práctica, en este caso daría igual, porque \(z_{\frac \alpha 2} = - z_{1- \frac \alpha 2}\) y al aplicar la fórmula con \(\pm\) el resultado serían los mismos límites. Sin embargo, en los intervalos bilaterales tenemos que poner cuidado con los cálculos.
Los intervalos unilaterales se deducen análogamente, pero acotando el valor de la distribución normal solo en una de las colas. Por ejemplo, para un intervalo unilateral por la derecha:
\[P\left[\frac{\overline x- \mu}{\frac{\sigma}{\sqrt{n}}}<z_{\alpha}\right] = 1-\alpha.\] Y el intervalo de confianza ahora será:
\[\boxed{\mu < \bar x + z_{\alpha}\cdot \frac{\sigma}{\sqrt{n}}}.\] Análogamente, para un intervalo por la izquierda, el intervalo de confianza será:
\[\boxed{\mu > \bar x - z_{\alpha}\cdot \frac{\sigma}{\sqrt{n}}}.\]
Nótese que en los intervalos unilaterales utilizamos \(z_\alpha\) en vez de \(z_{\frac \alpha 2}\). Esto es porque concentramos toda la probabilidad de error en una de las colas, lo que además reduce el error en la estimación. Por eso, cuando solo estemos interesados en uno de los límites, el superior o el inferior, siempre es preferible obtener intervalos unilaterales. La figura 8.3 muestra una representación de las tres situaciones.
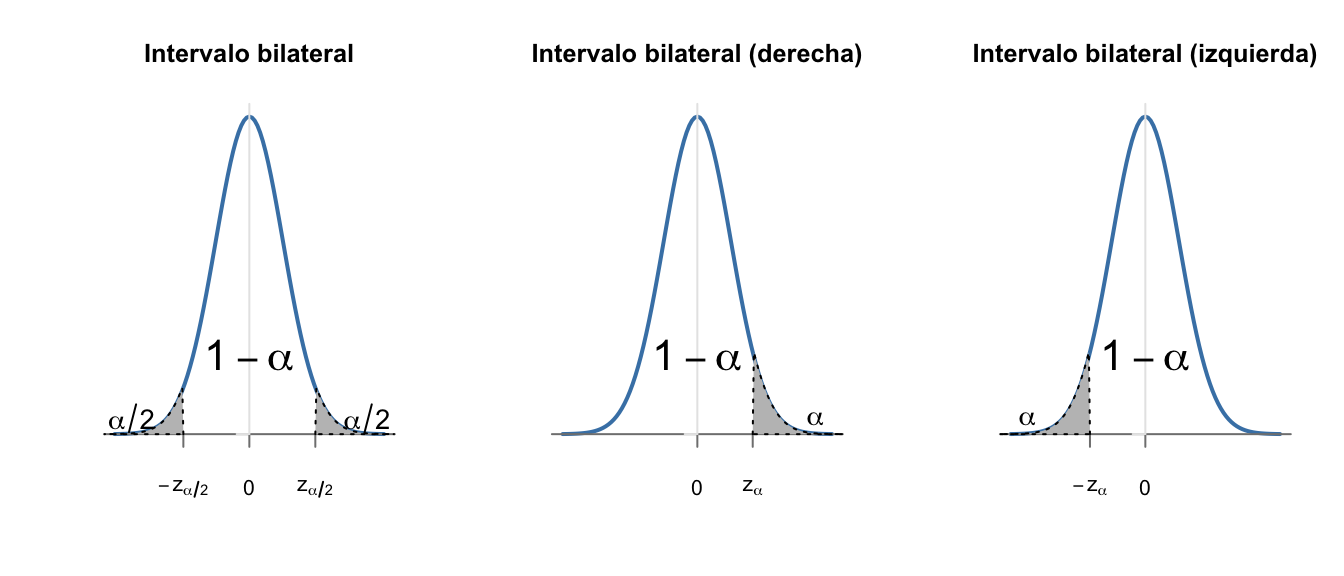
Figura 8.3: \(z_{\frac \alpha 2}\) o \(z_\alpha\), esa es la cuestión
En el ejemplo del antimonio, queremos obtener un intervalo de confianza al 99% para dar cuenta de la incertidumbre en la estimación puntual, pero con mucha confianza. Además, para aumentar la precisión de nuestra estimación por intervalos, solo nos interesa el límite superior, que es donde podemos tener el riesgo para la salud. Supongamos que la varianza es conocida, \(\sigma^2 = 0{,}0064\). Entonces el límite superior sería el calculado con la siguiente expresión. Esto quiere decir que, con una confianza del 99%, la media del antimonio en el agua potable es menor de 1,05 \(\mu\)g/l, muy lejos del límite marcado por la legislación (téngase en cuenta que hacemos estimaciones sobre la media, no sobre posibles valores individuales).
8.8.2 Intervalo de confianza para \(\mu\): \(\sigma^2\) desconocida
En la ecuación (8.3) asumimos que la varianza de la población \(\sigma^2\) es conocida. Pero esto rara vez lo podemos dar por hecho, y en su lugar lo que tenemos es una estimación a través de una muestra y el estadístico \(s^2\). Si sustituimos en la ecuación (8.2), la distribución en el muestreo ya no es una distribución normal sino una \(t\) de Student.
\[\frac{\overline X- \mu}{\frac{s}{\sqrt{n}}}\sim t_{n-1},\]
Para un nivel de confianza \(1-\alpha\) determinado, si buscamos un intervalo bilateral tenemos que:
\[P\left[-t_{n-1,\frac{\alpha}{2}}<\frac{\overline x- \mu}{\frac{s}{\sqrt{n}}}<t_{n-1,\frac{\alpha}{2}}\right] = 1-\alpha.\]
Y despejando \(\mu\) tendremos que, con una confianza de \(1-\alpha\), el verdadero valor del parámetro \(\mu\) estará en el intervalo:
\[\boxed{IC_\mu=\bar x \pm t_{n-1, \frac{\alpha}{2}}\cdot \frac{s}{\sqrt{n}}}\]
La distribución \(t\) de Student tiene un único parámetro \(n\), que son los grados de libertad. Sean las variables aleatorias \(Z, Z_1, \cdots, Z_n \sim N(0;1)\). Entonces, la variable aleatoria definida por:
\[T = \frac{Z}{\frac{1}{n}\sum Z_i^2}\sim t_{n},\] sigue una distribución \(t\) de Student con \(n\) grados de libertad, y que tiene las siguientes características:
\(E[T]=0\)
\(V[T]=\frac{n}{n-2}\)
\(n>30 \implies t_n \sim N(0;1)\)
En la práctica, obtendremos los valores \(t_{n-1; \frac\alpha 2}\) en tablas o con software, y sustituiremos los valores en la fórmula. O bien obtendremos directamente los intervalos con el software.
¿Por qué este nombre tan raro de la distribución? Realmente Student es el seudónimo que utilizó el estadístico inglés William Sealy Gosset para publicar el trabajo en el que la definió, ya que la empresa en la que trabajaba no permitía a sus empleados publicar con su nombre para no desvelar secretos industriales. A muchxs estadísticxs nos gusta la historia, y el producto que fabricaba la empresa en la que trabajaba el bueno de Gosset73.
Lo explicado en el apartado anterior sobre los intervalos unilaterales aplica exactamente igual a este caso, por lo que no lo repetiremos. La distribución \(t\) es también simétrica como la normal estándar, y prácticamente igual para \(n > 30\). La figura 8.4 muestra la distribución normal estándar y la distribución \(t\) para varios valores de \(n\).
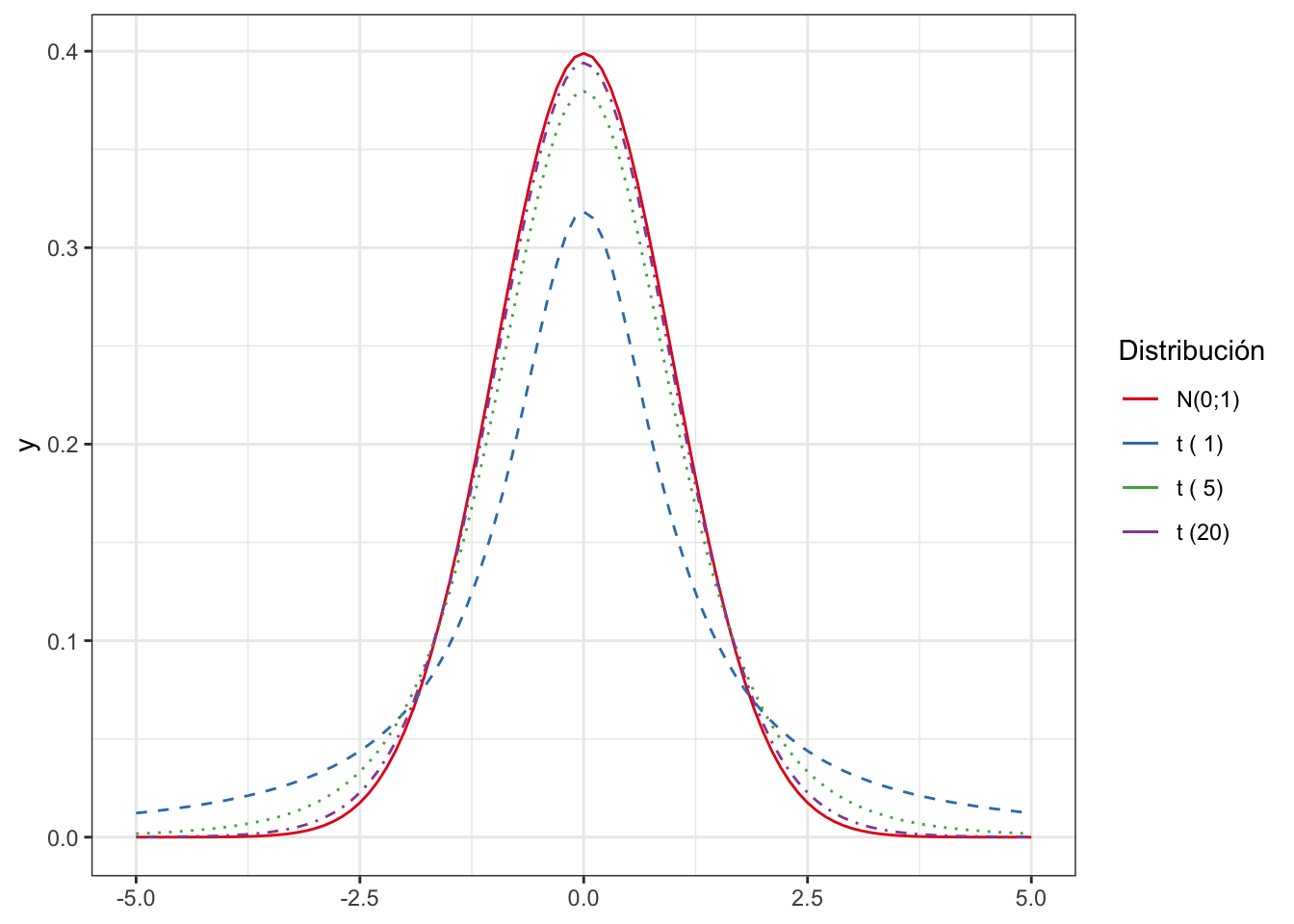
Figura 8.4: Distribución \(t\) vs la normal
Vamos a obtener los intervalos de confianza para el pH (bilateral) y para el antimonio (unilateral) de los ejemplos anteriores, pero en este caso asumiendo que la varianza es desconocida.
En este caso sí tenemos una función que nos proporciona el intervalo de confianza,
y es la función t.test(). En realidad calcula más cosas, pero obtenemos solo
el elemento conf.int que tiene el intervalo de confianza. El código a
continuación obtiene los intervalos de confianza pedidos. El argumento alternative
controla que sea bilateral (por defecto, two-sided) o unilateral (solo límite superior, less, o
solo límite inferior, greater). El argumento conf.level controla el
nivel de confianza (confidence level).
Nótese cómo, para la misma confianza, los intervalos obtenidos son más amplios al no conocer la varianza (tenemos menos información, y por tanto el error que cometemos es mayor).
Se deja como ejercicio comprobar que aplicando la fórmula como en los casos
anteriores, se tiene el mismo intervalo. El cuantil de la distribución \(t\)
lo obtendríamos con la función qt(), por ejemplo para el intervalo unilateral
al 95% de confianza:
qt(0.975, 29)8.8.3 Intervalo de confianza para la proporción
Por el teorema central del límite, si \(n>30\) la variable aleatoria “proporción muestral en muestras de tamaño \(n\)”, sigue una distribución normal con media la proporción poblacional \(\pi\) y varianza \(\frac{\pi(1-\pi)}{n}\). Por tanto, tipificando, tenemos la siguiente distribución en el muestreo:
\[\begin{equation} \frac{p - \pi}{\sqrt{\frac{\pi(1-\pi)}{n}}}\sim N(0; 1). \tag{8.4} \end{equation}\]
Para un nivel de confianza \(1-\alpha\) determinado, si buscamos un intervalo bilateral tenemos que:
\[\boxed{IC_\pi=p\pm z_{\frac{\alpha}{2}}\cdot \sqrt{\frac{\pi \cdot (1-\pi)}{n}}}.\] El parámetro \(\pi\) es desconocido y se sustituye por la proporción muestral \(p\). Los intervalos unilaterales se obtendrían de forma análoga a los de la media, acumulando la significatividad \(\alpha\) solo en uno de los extremos.
Vamos a obtener el intervalo de confianza bilateral para la proporción de edificios de viviendas con depósito de agua. Ya habíamos calculado la proporción muestral como \(p = 0.37\). El intervalo de confianza al 95% con la aproximación normal sería el siguiente:
\[IC_\pi=p\pm z_{\frac{\alpha}{2}}\cdot \sqrt{\frac{p \cdot (1-p)}{n}} = 0.37 \pm 1.96 \cdot \sqrt{\frac{0.37 \cdot 0.63}{30}}\\=[0.197, 0.543].\]
En general, esta aproximación es más conservadora (intervalos amplios) que otros métodos más precisos.
En R podemos obtener un intervalo exacto para la proporción de viviendas utilizando la binomial, y otro mediante la distribución chi-cuadrado que no vemos en más detalle. Este último aplica por defecto la llamada “corrección por continuidad de Yates” (Véase la ayuda de la función prop.test().
binom.test(x = 11, n = 30)
#>
#> Exact binomial test
#>
#> data: 11 and 30
#> number of successes = 11, number of trials = 30,
#> p-value = 0.2005
#> alternative hypothesis: true probability of success is not equal to 0.5
#> 95 percent confidence interval:
#> 0.1992986 0.5614402
#> sample estimates:
#> probability of success
#> 0.3666667
prop.test(x = 11, n = 30)
#>
#> 1-sample proportions test with continuity correction
#>
#> data: 11 out of 30, null probability 0.5
#> X-squared = 1.6333, df = 1, p-value = 0.2012
#> alternative hypothesis: true p is not equal to 0.5
#> 95 percent confidence interval:
#> 0.2054281 0.5609198
#> sample estimates:
#> p
#> 0.36666678.8.4 Intervalo de confianza para la varianza
La variable aleatoria que vamos a utilizar para construir el intervalo de confianza de la varianza es la siguiente:
\[\frac{(n-1)s^2}{\sigma^2}\sim \chi^2_{n-1}.\]
A diferencia de las distribuciones normal y \(t\), la distribución \(\chi^2\) no es simétrica (véase la figura 8.1). Entonces el intervalo tampoco lo va a ser. Es decir, el centro del intervalo no va a ser la estimación puntual de la varianza, y los límites hay que calcularlos con los cuantiles específicos.
A partir del nivel de confianza determinado \(1-\alpha\), establecemos la condición de probabilidad:
\[P\left[\chi^2_{n-1,\frac{\alpha}{2}}<\frac{s^2\cdot(n-1)}{\sigma^2}<\chi^2_{n-1,1-\frac{\alpha}{2}}\right] = 1-\alpha,\]
y despejando \(\sigma^2\) tenemos los límites del intervalo de confianza para la varianza como:
\[\boxed{IC_\sigma=\left[ \frac{s^2\cdot(n-1)}{\chi^2_{n-1,1-\frac{\alpha}{2}}}; \frac{s^2\cdot(n-1)}{\chi^2_{n-1,\frac{\alpha}{2}}}\right]}.\] Aquí, $ $ y \(1 - \frac{\alpha}{2}\) toman su sentido original al no ser simétricos como en la normal y la \(t\).
En el ejemplo del pH, teníamos la estimación puntual de la varianza como:
\[\hat{\sigma}^2= s^2 = 0.21\]
El intervalo de confianza se puede calcular a mano con la fórmula anterior,
teniendo en cuenta que los cuantiles de la distribución \(\chi^2\) se obtendrían
con la función qchisq(). No hay una función específica en R base para obtener
el intervalo de confianza, pero se puede calcular con las siguientes expresiones.
8.9 Intervalos de confianza para comparaciones
Uno de los principales usos de la estadística aplicada es la comparación de muestras para determinar si pueden venir de la misma población, o por el contrario se puede demostrar que hay diferencias significativas en algunos de sus parámetros. Normalmente estas comparaciones las haremos con los contrastes de hipótesis que veremos en el siguiente capítulo. No obstante, a veces es útil obtener intervalos de confianza para la diferencia de la media o para la razón de varianzas.
En general, tenemos dos muestras, \(x_1, x_2\) que posiblemente estén relacionadas. Se puede dar el caso de que las varianzas sean conocidas e iguales, conocidas y distintas, o bien desconocidas. Los tamaños de muestra de ambas muestras pueden ser iguales o distintos, por ejemplo \(n_1, n_2\).
8.9.1 Intervalos de confianza para la diferencia de medias
En el caso del intervalo de confianza para la media de dos muestras, estaremos interesados en la diferencia de medias, \(\theta = \mu_1- \mu_2\). Entonces, como las medias siguen una distribución normal, entonces aplicando las propiedades de la esperanza y la varianza:
\[\frac{\bar{x}-\bar{y}-\theta}{\sqrt{\frac{\sigma_1^2}{n_1}+\frac{\sigma_2^2}{n_2}}}\sim N(0;1)\]
Entonces, para varianzas conocidas tenemos que el intervalo de confianza para la diferencia medias: \(\mu_1 - \mu_2\), \(\sigma_1. \sigma_2\) conocidas es:
\[IC_{\mu_1-\mu_2} = (\bar x_1 - \bar x_2) \pm z_{\frac \alpha 2}\sqrt{\frac{\sigma_1^2}{n_1}+\frac{\sigma_2^2}{n_2}}\]
Para el caso de varianzas desconocidas, pero que se pueden asumir iguales \((\sigma_1 \ne \sigma_2)\), se calcula la varianza agrupada, o conjunta (pooled) como:
\[s_p^2= \frac{(n_1 -1)s_1^2+(n_2-1)s_2^2}{n_1+n_2-2},\]
y entonces a través de la siguiente distribución en el muestreo:
\[\frac{\bar{x}-\bar{y}-\theta}{s_p\sqrt{\frac{1}{n_1}+\frac{1}{n_2}}}\sim t_{n_1+n_2-1}\]
obtenemos la siguiente expresión para el intervalo de confianza de la diferencia de medias con varianzas desconocidas pero iguales:
\[IC_{\mu_1-\mu_2} = (\bar x_1 - \bar x_2) \pm t_{n_1+n_2-2, \frac \alpha 2}\cdot s_p\sqrt{\frac{1}{n_1}+\frac{1}{n_2}}.\] Por último, en el caso en que las varianzas son desconocidas y no se puede aceptar que sean iguales \((\sigma_1 \ne \sigma_2)\), tenemos la siguiente distribución en el muestreo:
\[\frac{\bar{x}-\bar{y}-\theta}{\sqrt{\frac{s_1^2}{n_1}+\frac{s_2^2}{n_2}}}\sim t_f,\]
donde:
\[f=\left[ \frac{\left (\frac{s_1^2}{n_1}+\frac{s_2^2}{n_2}\right )^2}{\frac{\left(\frac{s_1^2}{n_1}\right)^2}{n_1-1}+\frac{\left(\frac{s_2^2}{n_2}\right)^2}{n_2-1}}\right],\]
redondeando al entero menor. Y entonces el intervalo de confianza es:
\[IC_{\mu_1-\mu_2} = (\bar x_1 - \bar x_2) \pm t_{f, \frac \alpha 2}\sqrt{\frac{s_1^2}{n_1}+\frac{s_2^2}{n_2}}.\]
Este método se conoce como la aproximación de Welch.
En el conjunto de datos del pH podemos comparar estimar intervalos de confianza para la diferencia en la media del pH entre los edificios que tienen depósito de agua y los que no. La función t.test() que ya utilizamos para el intervalo de confianza de la media no sirve para este nuevo intervalo de confianza. Por defecto asume varianzas desconocidas y distintas (correción de Welch). Con el argumento var.equal se puede cambiar este comportamiento por defecto.
t.test(pH ~ deposito, data = ph1)
#>
#> Welch Two Sample t-test
#>
#> data: pH by deposito
#> t = -0.92268, df = 27.004, p-value = 0.3643
#> alternative hypothesis: true difference in means between group No and group Sí is not equal to 0
#> 95 percent confidence interval:
#> -0.4373191 0.1660081
#> sample estimates:
#> mean in group No mean in group Sí
#> 7.991526 8.127182Cuando las muestras están relacionadas, habría que proceder de forma distinta. En vez de calcular las medias de los dos grupos y después hacer la diferencia, habría que calcular las diferencias de las observaciones relacionadas, y entonces trabajar con esa variable aleatoria \(Y = X_1 - X_2\). Por ejemplo, supongamos que en el estudio del pH volvemos a hacer mediciones al cabo de un tiempo después de aplicar un determinado tratamiento a las aguas de la ciudad. Entonces tendremos otras 30 mediciones en los mismos edificios, y haríamos la diferencia entre el tiempo 2 y el tiempo 1 de cada una de los 30 edificios. A partir de ahí se obtendría el intervalos de confianza de la media de la diferencia.
8.9.2 Intervalo de confianza para la diferencia de proporciones
Aplicando el teorema central del límite y la aproximación normal para muestras grandes, tendremos que si \(\theta = \pi_1-\pi_2\):
\[\frac{p_1 - p_2 - \theta}{\frac{p_1(1-p_1)}{n_1} + \frac{p_2(1-p_2)}{n_2}}\sim N(0; 1).\] y entonces el intervalo de confianza para la diferencia de proporciones será:
\[p_1-p_2 \pm z_{\frac \alpha 2}\cdot \sqrt{\frac{p_1(1-p_1)}{n_1} + \frac{p_2(1-p_2)}{n_2}}.\]
8.9.3 Intervalos de confianza para la razón de varianzas
Para comparar varianzas y dar intervalos de confianza de su diferencia, no podemos seguir el mismo proceso que con las medias, ya que las varianzas son siempre positivas, y la diferencia nunca va a ser cero. En su lugar, aplicaremos que las varianzas serán iguales cuando su cociente sea igual a 1. Es decir, usamos el parámetro \(\theta = \frac{\sigma_1^2}{\sigma_2^2}\) y la distribución en el muestreo siguiente:
\[\frac{s_1^2}{s_2^2}\cdot \frac{1}{\theta}\sim F_{n_1-1;n_2 -1},\]
donde F es la distribución F de Fisher-Snedecor, en la cual tenemos \(X_1, \ldots, X_{n_1}\); \(Y_1, \ldots, Y_{n_2}\) variables aleatorias independientes e idénticamente distribuidas normales tipificadas, \(\sim N(0;1)\), de modo que:
\[F = \frac{\frac{ 1}{ n_1}\sum\limits_{i=1}^{n_1} X_i^2}{\frac{ 1}{ n_2}\sum\limits_{i=1}^{n_2} Y_i^2}\sim F_{n_1,n_2},\]
y que tiene las siguientes propiedades:
\(E[F] = \frac{n_2}{n_2-2}, \; n_2>2\).
\(V[F] = \frac{2n_2^2(n_1+n_2-2)}{n_1(n_2-2)^2(n_2-4)}, \; n_2>4\).
La distribución F puede tomar muchas formas dependiendo de los grados de libertad de numerador y denominador. Algunas combinaciones se muestran en la figura 8.5.
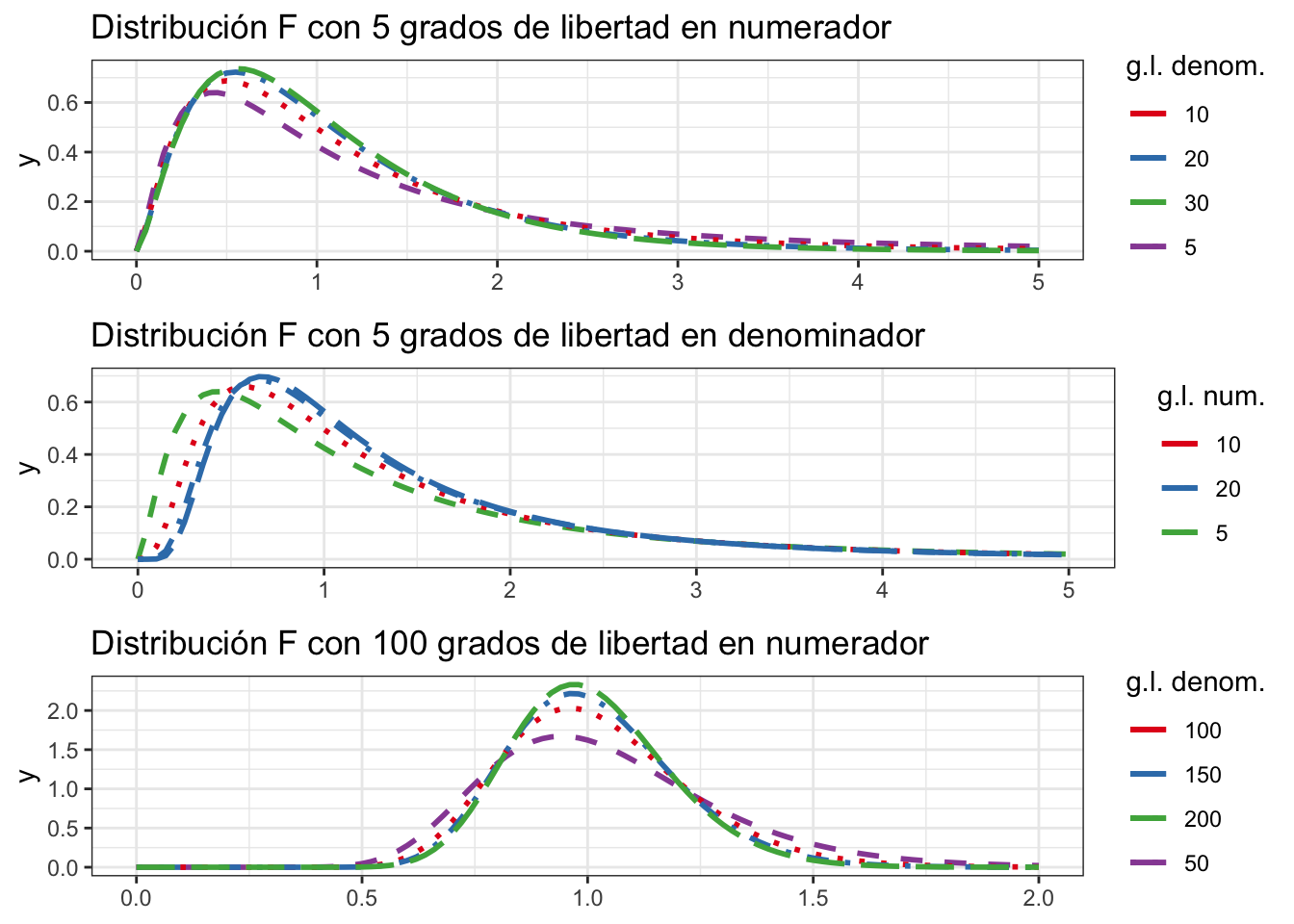
Figura 8.5: Forma de la densidad de F para varias combinaciones de parámetros
Entonces el intervalo de confianza para la razón de varianzas se calcularía como se indica a continuación:
\[IC_{\frac{\sigma_1}{\sigma_2}} = \left[\frac{\frac{s_1^2}{s_2^2}}{F_{n_1-1, n_2-1, \frac{\alpha}{2}}};\frac{s_1^2}{s_2^2}\cdot F_{n_2-1, n_1-1, \frac{\alpha}{2}} \right].\]
Vamos a calcular un intervalo de confianza para el cociente de varianzas de los edificios que no tienen depósito y los que sí tienen depósito. La función var.test() nos da este resultado. Nótese que el intervalo no contiene al 1, y por tanto no es compatible con que las varianzas sean iguales. Esto se podría utilizar para decidir si tenemos varianzas iguales o no al calcular un intervalo de confianza de la diferencia de medias.
var.test(pH ~ deposito, data = ph1)
#>
#> F test to compare two variances
#>
#> data: pH by deposito
#> F = 4.7878, num df = 18, denom df = 10, p-value =
#> 0.01526
#> alternative hypothesis: true ratio of variances is not equal to 1
#> 95 percent confidence interval:
#> 1.386414 13.723673
#> sample estimates:
#> ratio of variances
#> 4.787814Los intervalos de confianza de las comparaciones, además de la propia incertidumbre acerca de la estimación puntual del parámetro diferencia (o cociente), nos permite realizar las siguientes interpretaciones:
Si el intervalo de confianza de la diferencia de medias contiene el cero, no podremos asegurar que haya diferencias entre las medias de las dos poblaciones (en general, nos interesará confirmar que sí hay diferencias).
Si el intervalo de confianza de la razón de varianzas contiene el 1, no podremos asegurar que haya diferencias entre las varianzas (en general, nos interesará comprobar que no hay diferencias).
O lo que es lo mismo, las diferencias observadas en las muestras son debidas al azar, y no a una diferencia real entre los parámetros poblacionales.
Esto lo hacemos también con contrastes de hipótesis en el siguiente capítulo.